
Intent Is the Interface
The screen was a constraint we mistook for the product.

We design interfaces. Pixel arrangements on glass. Then we redesign them for smaller glass. Then for round glass on wrists or in our faces. Then for no glass at all—voice, chat, agents.
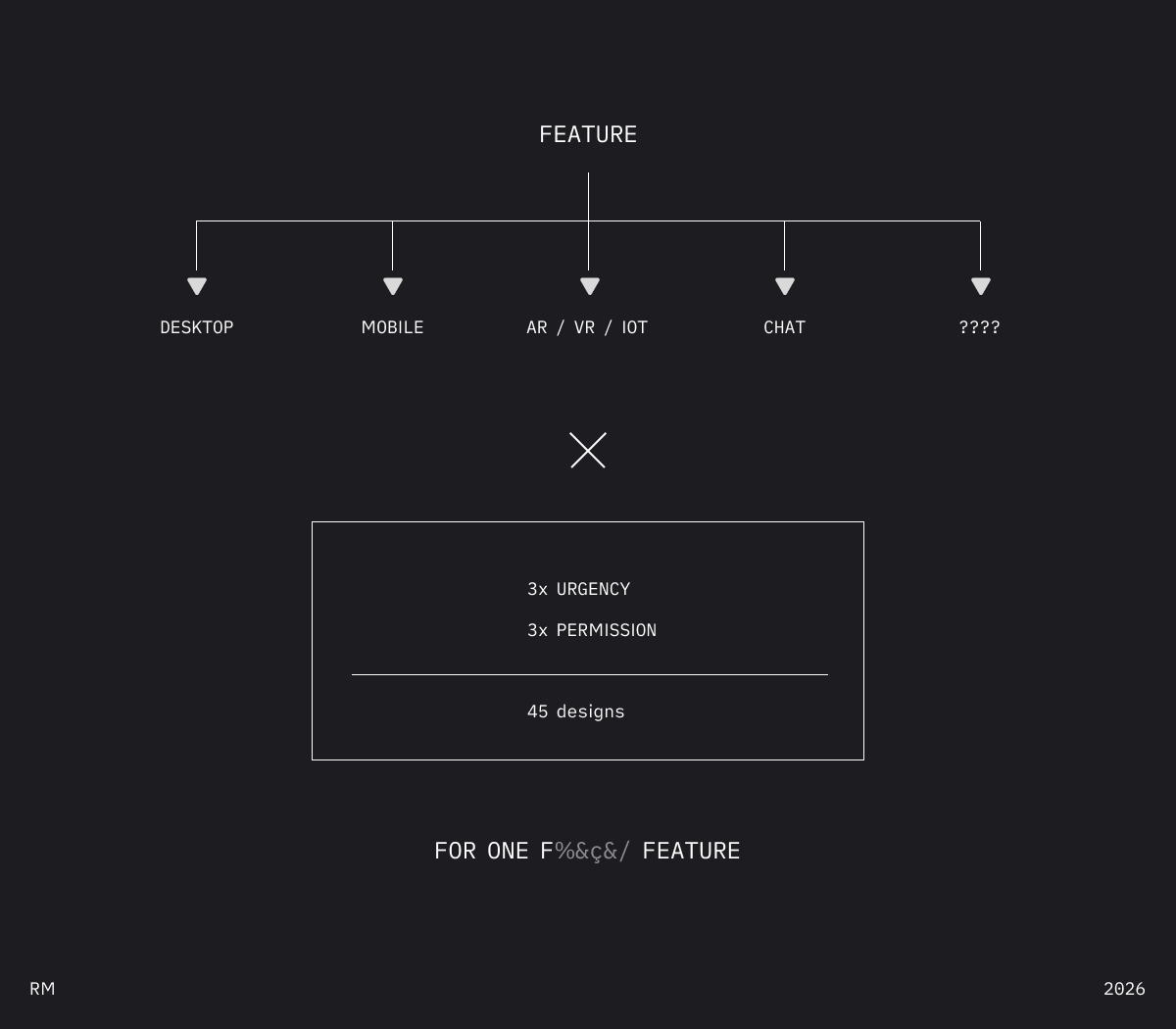
If you’re shipping to more than two surfaces, you’ve felt this.
We're designing the wrong unit.
An interface is an appearance. An appearance of what?
A capability. The thing users can actually do.
“Request a ride” is a capability. The app screen is one appearance. The voice command is another. The watch tap is another.
Decades refining shadows. The object casting them got neglected.
Think of capabilities as cells in a petri dish. They exist before you observe them. The microscope determines what you see—not what’s there. We’ll come back to this.
Capabilities decompose into intents.
Audit any interface. Every action maps to a small set of patterns. Here are eight. There may be more. These cover most of what we build:

Uber's "Request Ride"—three intents:

Same capability. Three projections:
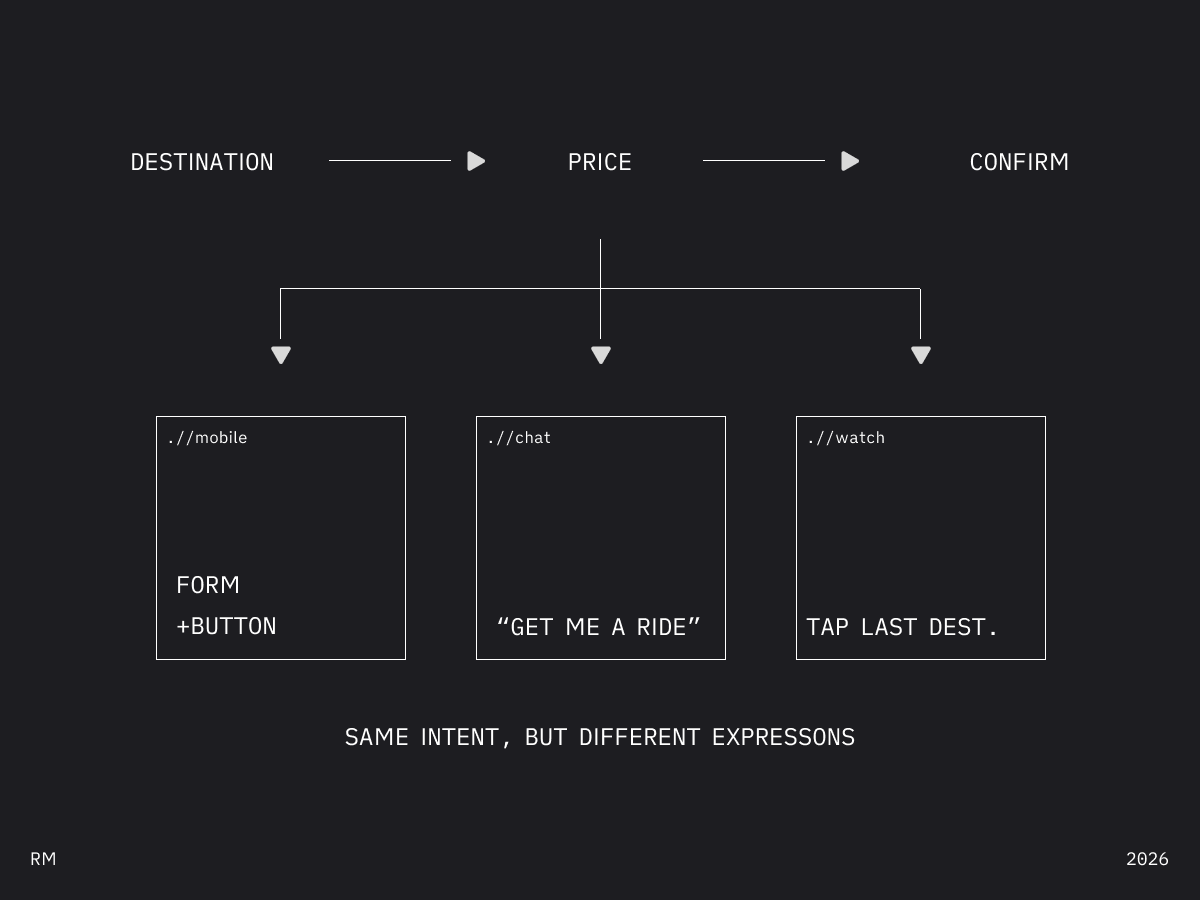
Now add context.
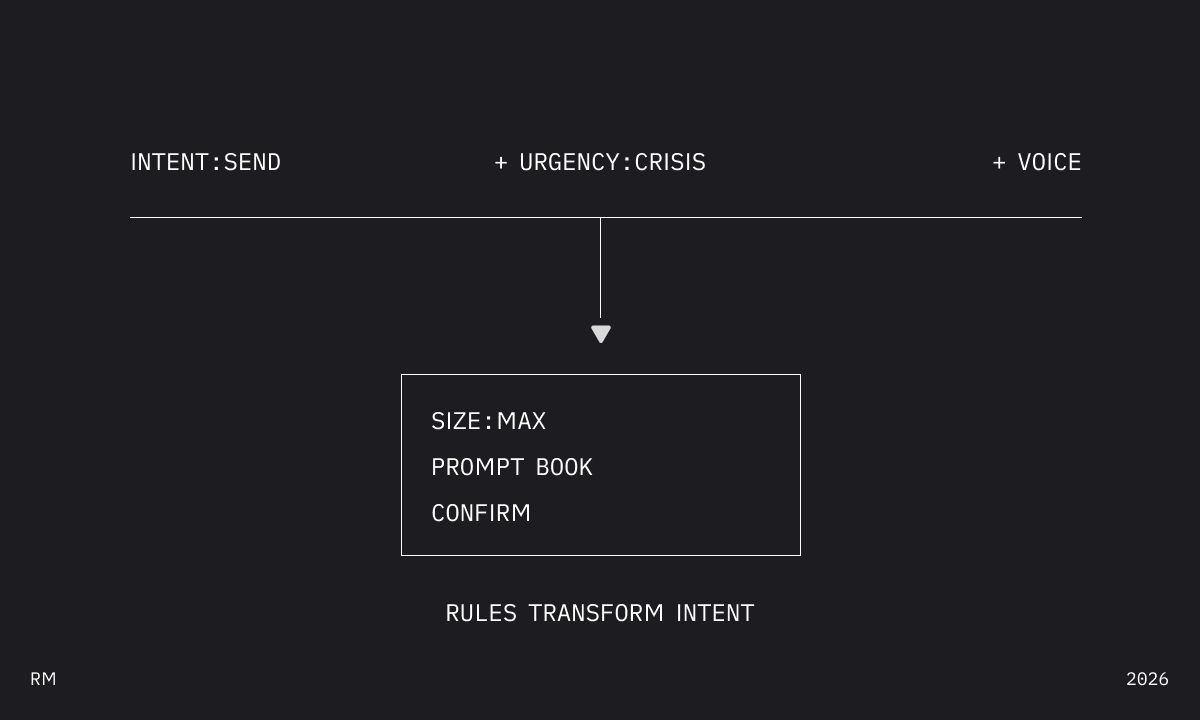
send during calm = button with confirmation. send during crisis = full-screen, no confirmation, haptic feedback.
Same intent. Different situation. Different expression.
Context isn’t screen width. That’s one dimension. There are at least six:

The interface isn't designed. It's derived.
AI broke two assumptions.
First: interfaces live on screens. Conversation has no viewport. An agent has no interface at all—until it needs to show you something.
Second: users initiate.
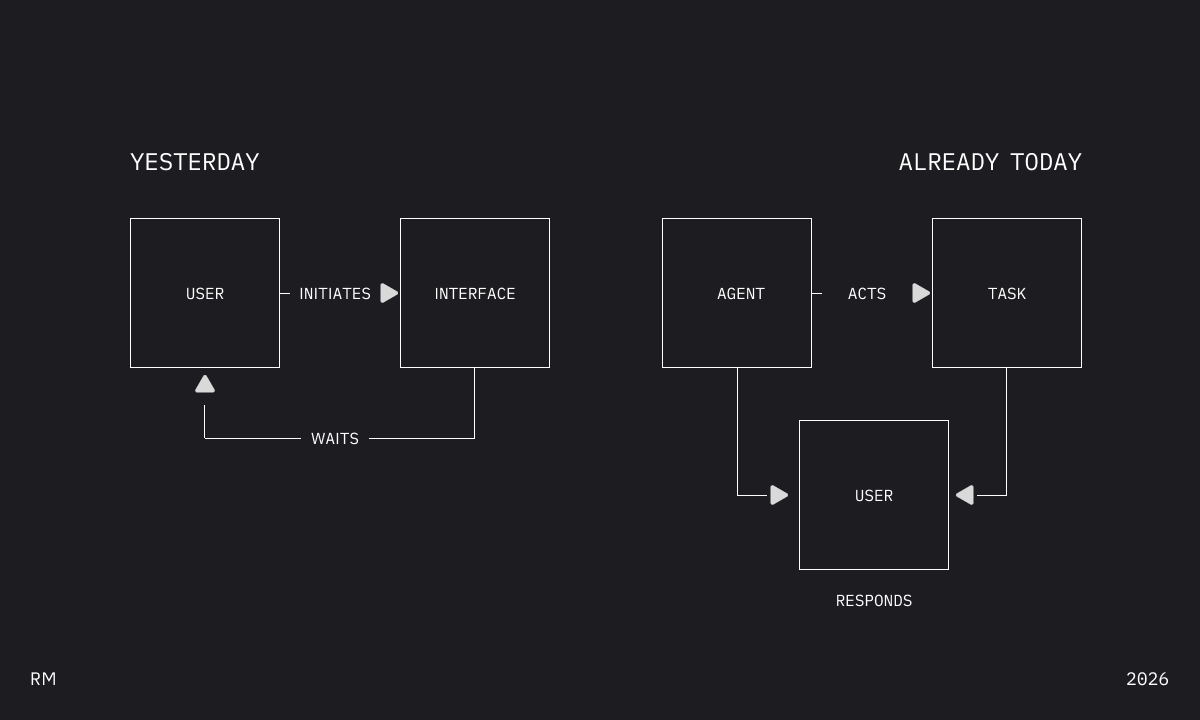
For fifty years, design assumed you start things. Click. Tap. Navigate. The interface waits.
Agents invert this. They act, then surface for approval. You respond.
You’re not initiating. You’re reacting. The interface isn’t a tool you operate—it’s a negotiation you manage.
A reactive interface can’t be a static layout. It needs context: what surface, what you’re doing, how urgent, whether you need full control or just yes/no.
Systems built around screens will bolt AI on awkwardly.
Systems built around intents will treat AI as another projection surface—one where the agent initiates and the human responds.
Why hasn't anyone properly done this?
Because it’s hard.
State management across projections. Context detection that guesses wrong. UI that shifts and feels uncanny. Rule systems that explode in complexity.
These are real problems. Unsolved.
But “hard” isn’t “impossible.” And the alternative—45 interfaces per feature, designed by hand—is already impossible. We just pretend otherwise.
The potential paradigm shift:
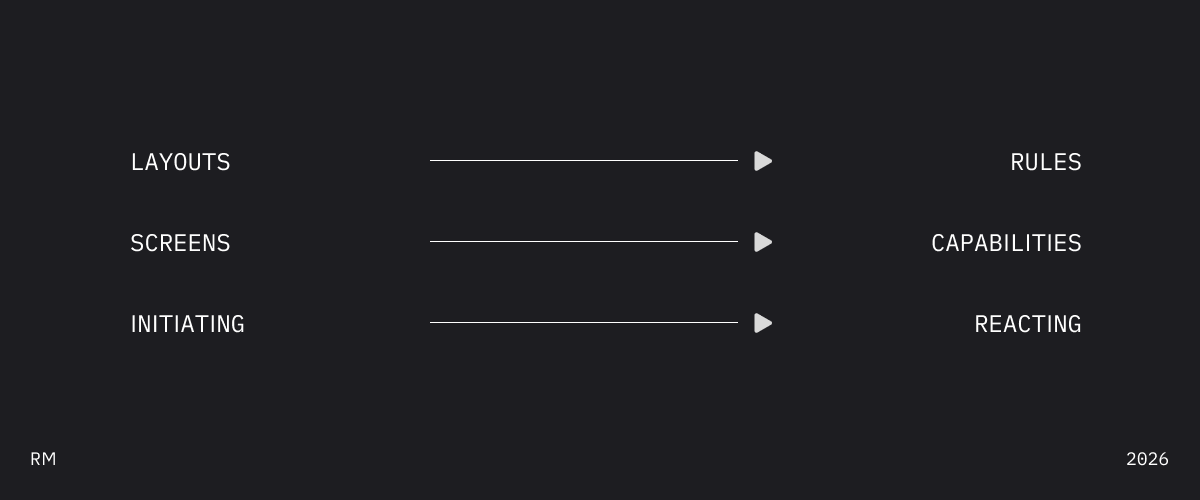
Stop designing how things look.
Start designing what things do.
Intent is the interface now.
Remember the petri dish.
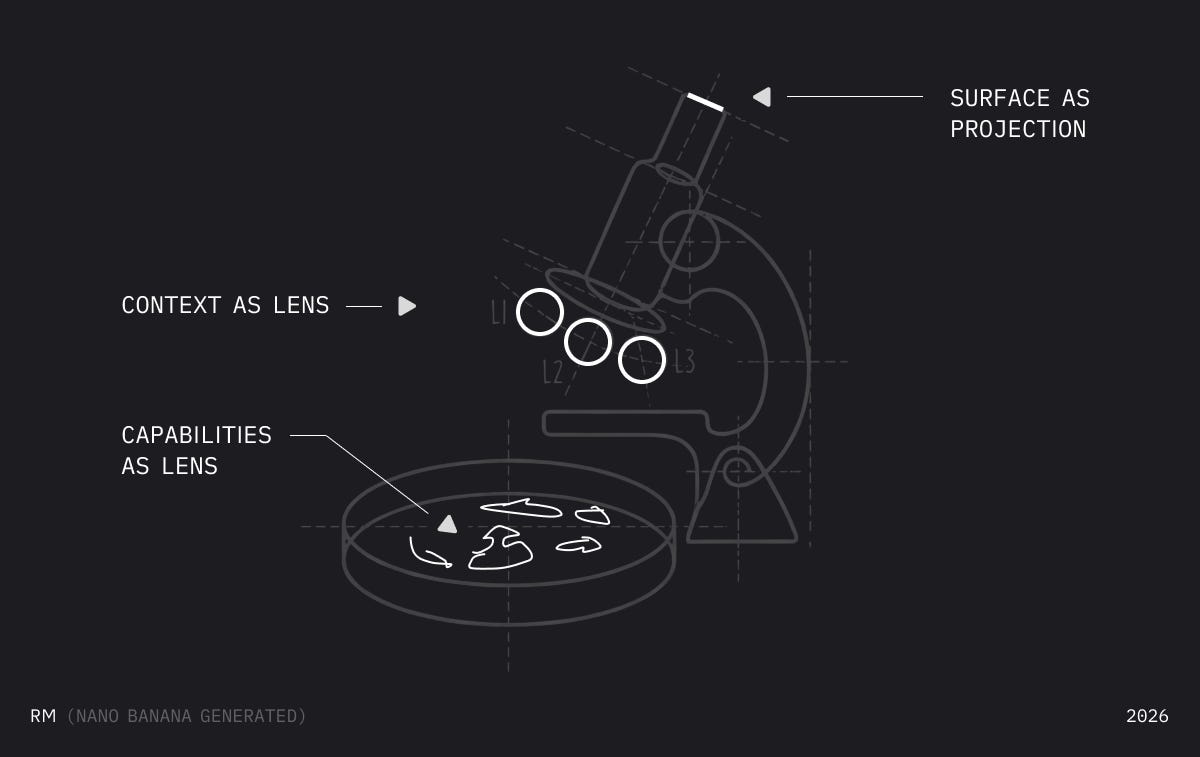
Capabilities live here—breathing, connected. Adjust the lens, see different projections. This is what design tools look like when they stop assuming screens.
What if “experience is just intent zones”.
Stop designing screens. Start describing intent and capabilities.
Place intents (search, create, read, navigate) on a canvas. Hover any intent zone → see it rendered across desktop, mobile, voice, and API simultaneously.
One input. Infinite surfaces.
Cheers. RM
This post was written in one session using Claude Opus 4.5 through Quick Capture. I dumped a mess of voice notes, discussion guides, and half-formed bullet points into the context window and we shaped it together through a few editing passes. The ideas are mine, the speed is new. (I did make the frameworks manually though.)